2017年4月に兵庫県立大学のシミュレーション科学専攻の博士後期課程に入学し、 2018年から19年はじめにかけて査読論文を2つ書いて、2020年3月に無事終了しました。 テーマは大規模有向(リンクに方向性があるタイプ)グラフの可視化と、これを用いた大規模ネットワーク分析です。 この記事では、 データ分析を受託する事業と中央官庁で政策のためのデータ整備、分析する業務を続けながら、 同時にデータ分析についての学術研究を行い、学位取得に至るまでのいきさつを紹介します。 私にとってデータ分析は生活のための手段であり、学術的な興味の対象ではありませんでした。 すなわち、成果とは金銭的対価であり学術的価値ではありません。 他の事業者では不可能な分析を、他の事業者では不可能な価格で提供することで市場で評価され、対価を得るのです。 しかし、学位論文をまとめてゆくうちに、データの背後に存在する基礎的な原理に気づくことで、 学術的なモチベーションを獲得します。 こうして、人類の知的限界を克服し新たな知見を加えることを自分の仕事を通して行うことにも価値を見出すようになるのです。 これはそういう話です。
Royal Society にその起源をもつ近代の学術研究は、暮らしに不自由のないひとが自由意志にもとづいて行った学術的に価値のある 仕事とその報告、という存在です。そのようなものでなければならない、とする定義はどこかを探せばあるのかもしれないし、あるいは(イギリスらしく)成文化されたものは存在しないのかもしれません。しかし、査読のある学術論文を主要な著者として作成した経験があれば、この定義を所与のものとして共有しているのではないでしょうか。
「暮らしに不自由のないひとが自由意志にもとづいて」と書くと実に嫌味ったらしく鼻持ちならないものに思えますが、 これは学術の正確さを保つ上で可能な限り尊重されねばならない原則でもあるのです。
近代以前の学術は、特権階級の占有物であり、総じて善意と真理への欲求にもとづくものではありましたが、 しばしば自分たち以外を蔑視、抑圧、搾取することを正当化し、かつそれを実行するためのスキルでもありました。 したがって、暮らしに不自由のないひとが自由意志にもとづいてそれらを行うのだという原則は完全に内面化されており、 そのためにかえって「我々は暮らしに不自由していないので自由意志にもとづいてこれをやっています」と言語化されることはなかったのです。真理は権力と一体不可分であり、誤謬はそのまま失脚や敗北を意味していました。たとえば教会で教義に関する議論を行って敗北すれば、それは異端であることを意味し、追放や死刑を含意しました。
啓示宗教が求心力を失い、市民社会と科学技術が発達することによってこの状況は覆えりました。 それは知識の担い手が教会から大学に推移していくプロセスでもありました。 近年では論文を投稿する際に "Conflict of Interest" についての宣言を求められるわけですが、 これは、その報告が自己の利益を誘導するものではなく、したがって、誤りがあったとしてもそれは偶然か、 あるいは技術的な困難によるものであり、そのような過ちはいずれにしても避けられないものであるからには、 当該報告に含まれる誤りは最小化されている、ということを社会的に担保するための仕組みなわけです。
これを別の言い方をすれば、「暮らしに不自由のないひとが自由意志にもとづいて」となるわけです。 いうまでもなく科学技術はビジネスにも戦争にも用いる事ができるわけですから、 利益を誘導するために真実をねじまげた報告がなされることは充分にありえますし、現実にこれが分野全体を非常に難しい状態に 陥れている場合があることは、一般メディアを騒がす捏造などでもお馴染みのとおりです。
近代初期の学術研究の担い手はブルジョワか貴族でした。 当時はどのような学術研究であれ、そのレベルの富の集中を必要としたのです。 しかし徐々に学術研究は高度化、大規模化し、金持ちの道楽に収まらなくなった結果、 広くすべての市民から適性をもった人材を選抜して、 身分を保証することで「暮らしに不自由のない」状態を制度化するようになりました。職業人としての研究者の誕生です。 身分を保証するのは国家や企業や宗教です。
申し遅れましたが、私には一切の身分保障がありません。私が業務を行うのは顧客のためであり、 たまたまその結果が人類の知的限界を克服するだけです。 得られた知見を既存の学術から解釈することでその価値を体系的に付与し、解釈に用いた文献の一覧とともに提出する、 という作業には相当の時間が必要であり、全く経済合理性がありません。
また、ビジネスにおける課題の解決は既知の権威ある手法でなされるほど好ましいものです。 解答に価値を与えるのは学術界ではなく顧客であり市場です。彼らが支出を工面するのは経済合理性があるからです。 皆さんも、自分のビジネスの課題は、未知の技術的に高度な方法ではなく、もしできれば昔からある広く知られた権威ある手法で 解決してほしいのではないでしょうか。 既知の手法で新たな課題を解決すればそれはビジネスチャンスになりえますが、 未知の手法で既知の課題を解決してもおもしろいだけで、カネにはなりません。
そこで問題は次のように定式化されます。
身分の保証の無い者がカネのために動く状態で、学術的文脈から価値があると判断される業績あげることは可能か?
本稿は以下のように構成されています。
安価で高性能なコンピュータ、自由で高機能な計算環境、そして高速なデータ通信が完備した現代でなければ、研究に必要な業務生産性、 これは余剰時間と読み替えることができるわけですが、そのような生産性を確保することは不可能だったでしょう。本章ではオープンな高速データ通信と自由な計算環境がもたらす高い生産性と「暮らしに不自由のない自由民」の関連について述べます。
かつて2000年頃から2007年はじめにかけて、私は会社をやっていたわけですが(その会社はもう存在しません) そこでは企画からテストまで、出荷と経理以外のすべての業務を私がやっており、数千万円の売上がありました。 これなら自分らが生きていくためだけなら週二日も働けばいいのではないか? つまりこれはもうすでに人生がアガリ状態なのでは? その余剰分を全部自分の学術研究につぎこめば、身分保証の不動点を構成することができるのではないか。
不動点とはつまり、自分の身分を自分が保証している状態、身分保証を関数と見なしたときに値が変化しない点、という意味です。
このような生産性が可能になるには個人の能力だけでは不十分というよりはむしろ、環境と偶然という要素がほとんどを占めていると考えるべきです。
これら三つの環境要因をはじめに挙げました。最初の要素については自明かと思いますが、のこる二つについてはかならずしも自明では ないと思うのでこれについて少し述べたいと思います。
高速で開かれたデータ通信網はいうまでもなく、ジ・インターネットのことです。「高速」もじつは全く自明ではありませんが、 今問題になっているのは「オープン」のほうで、インターネット上にサーバを開設し、様々なサービスを提供する事は 日本では誰でも可能なのであり、免許も講習も登録も不要なのです。
これはそれ以前の常識からすると異常なことで、たとえば勝手に電話局を開設するのは(よくしりませんが)多分不可能だと思います。 しかし、インターネットの通信制御はすべて公開情報で、その制御を行う機器類も一般に販売されており、さらに言えばここ10年ぐらいは、 いちいち機器を買ってこなくてもネットワーク・アクセスさえあればサーバを間借りしてサービスを開始できるのです。
特定の設計の計算機と組み合わさって動作するオペレーティング・システムは、長らく計算機メーカーの有力なビジネス慣行でしたが、 インターネットの発展とともに非常に大規模で高度なソフトウェアがインターネット上の共同作業として作成されるようになると、 このビジネス慣行が経済合理性を維持するのは困難になっていきました。 じつは情報処理技術における自由を尊ぶ伝統にはインターネット普及以前からの長く偉大な歴史があるのですが、 「計算の自由」というイデオロギーはインターネットというインフラを得て はじめてお題目を超える真の力を持ったのでした。
自由に設計を参照し必要に応じて改造できるオペレーティング・システム。 その上で動作する、設計を参照し改造できる多様なプログラミング環境。 これらがオープンなネットワークに接続されており、 達人ユーザからワザを伝授してもらえるわけです。 たまたまこのような夢のようなインフラと環境が利用可能でなければ、 私という個人がそれだけの生産性を持つことは到底不可能でした。
実際、かつての大学は文献検索も不十分で、図書館でサーベイをしていると全く進捗がなく、 そのうち問題自体への興味も失ってしまうということを繰り返して大学院の中退に至ってしまったわけで、 私の生産性は個人の資質というより環境と偶然の産物なのです。
こうして、充分に幸運な(あるいはそれが過剰な謙遜に見えるのであれば「充分に訓練された」と言っても構いません)個人は自己のパトロンになることが可能な時代が実現したわけです。
これで身分の問題は解決しました。残る問題は「自由意志」です。
ここでは実際の研究の進展、特にモデル研究を手がけるようになったいきさつを紹介します。
博士課程の指導教官は兵庫県立大学 大学院シミュレーション学専攻の藤原義久先生です。藤原さんは私が情報通信研究機構(以下NICT)に所属していた時の先輩で、 出身は理学部物理、学位論文は宇宙論です。かつて東工大の情報科学専攻には位相幾何のゼミがあり、私も所属していたわけですが、 藤原さんもそこに客分として出入りしていたという事情もあり、NICT所属時にはずいぶんお世話になりました。
NICTで何をやっていたかというと、大規模複雑ネットワーク解析プロジェクトの所属で、 天体物理の重力計算のコードを応用して大規模グラフのレイアウトをやる、というのを担当していました。 それをそのままひきついで、 私の研究計画は、大規模かつ複雑な有向グラフの可視化とそれを使ったネットワーク解析をやる、 というもので、じつは入学時点で関連したテーマの査読論文が和文2英文2の4本がありました (これらは学位審査請求の要件には算入できません)。また、必要なツール類もNICT時代に概ね作成しており、 ビルドし直す程度の手間で使えるようになるわけです。
データについては、理化学研究所が京コンピュータを、社会実装されるような研究で活用するよう 設定したプロジェクトに藤原さんの研究が採択されていて、その予算で私も東京商工リサーチの企業相関データベースが使えました。 このデータは一般に金融機関が与信などに使うものですが、政府系の研究所なども金融政策研究などの目的で活用しているのです。
入学年度は単位をそろえるために機械学習の集中講義に出席し、その傍ら手持ちの解析結果のうち論文に使えそうなものを まとめて2本ほど投稿したところ、見事不採録となってしまいました。同時に、 役所で手がけていたプロジェクトも爆発炎上し、2017年はひたすら消耗するだけの最悪な一年となってしまいました。
不採録として却下されたとき、藤原さんから「論文では読み手に配慮するよりも、できるだけ厳密な表記を選んだ方が良い。」 という助言をもらいました。 それからは、曖昧な表記を常に避けて指標類やアルゴリズムの記述にはすべて数学的表記を使うようにしています。
おそらく、そういう表記を作れるという事自体が論文の品質をなにがしか担保する、という事情もあるかもしれません。そういう認知の不具合を攻略して採録されていた論文が最近まとめて撤回された、という事件が先日ありました。
しかしながら、実はこの方式には著者にとって見逃せない利点があるのです。それは、主張の杜撰さのチェック機能です。 自分が言っているのは何についての主張なのかを明確にし、考慮すべき全ての対象について網羅しているかを検討する助けになるのです。 まぁ検討するのは著者なのですが。
2018年度は持続的な経済成長と外生的ショックへの柔軟性を両立する企業間取引構造を企業相関の時系列可視化で解明した報告と、WWWサイトのリンク構造に見られる特異な性質を特定する定量的な指標の2報が採録されました。
このうち2報めのWWWの解析では、 いままでは可視化のアルゴリズムの説明でしか使ってこなかった数式を、解析の記述にも使うようになりました。 測定結果を表す複数の変数からなるなんらかの方程式を使って、 「ここではこんな事が起きています」という話を書くわけです。
この、解析対象となっているイベント中に存在する仕組みの部分を数式で表現したものを、業界では一般に「モデル」といいます。
モデルというのは便利な言葉で、領域によって含意がかなり違うので安易に使わない方が良い言葉なのですが、 だいたい共通するのは実際に起きているものごとに対置される理論的な検討対象というぐらいの意味ではないでしょうか。 ネットワーク解析では、解析対象となっている大規模な関係性が発生したそもそもの仕組み、 その上を伝播する情報、状態、金銭、物資を測定した値を表す変数を含んでいる数式の組み合わせとして 表記される場合が多いと思います。
なぜこれに手を出すようになったか、というと話は長いのですが、 データ分析をやっていると、その背後に特有の仕組みを背負った確率分布に常に直面しつづけることになります。 正規分布なら中心極限定理、対数正規分布なら対数に中心極限定理が成り立つような仕組みが背後にあるわけです。
同様に、巾分布(\(P(x)=cx^{-a}\) となるタイプの分布)にも特有の仕組みがあります。この仕組みから実際に \(P(x)=cx^{-a}\) を導出するのはかなり煩雑ですが、仕組み自体は非常に簡明かつ、広くみられる現象なので、 なるほどこれなら自分にもモデルが作れるのではないかという悟りが開けたわけです。
データ分析では「なぜそうなっているのか」を解明することには、ビジネス上でも学術上でも共通して、非常に価値があります。 学術上の意味があるのは自明ですが、 ビジネスに現象の仕組がどう関係するのでしょうか?
それは、仕組みがわかっていれば経営的判断の対象になりえるものとそうでないものが見分けられるからです。 たとえば経営上の障害となっている現象の背後にある仕組みが 「これは人類が進化の過程で獲得してしまった性質であり、我々の一存ではどうにもなりませんね」 ということがわかるならば、誤った投資を避けられます。これはビジネス上非常に大きな利点です。
もし現象を数式で表記するという慣習を取り入れなければ、このような発想に到達することは無かったでしょう。
2018年はこのように学位請求要件に向けて前進した、一転して生産的な一年でした。しかし、読者諸賢は覚えておられると思いますが、自由意志の件は依然として未解決のままです。
学位請求要件を構成する査読論文(研究の成果ですね)をまとめて一つの論文にして、それを審査してもらうと学位がもらえます。
そこまで貯まっていた仕事は、実体経済の取引ネットワークの構造の時間変化が持っている特徴と、WWWのリンク構造の特徴(とそれを指標化した式) の二つで、共通点としては「構造的特徴」だけです。要するにつながり方に関する特徴がありますよ、というわけです。
あとは、データの種類も違うし、片方は時系列で片方は特定日時のスナップショットだし、全然違う話です。
これを一つの話にするのはあからさまに無理な話なので、半年ぐらいは何もせんままに経過してしまいました。 モチベーションが枯渇したとも言えるし、その時点で調達可能なモチベーションでは挑戦する気にならないような難しい問題だったとも言えます。
博士課程入学前に何本か論文を作成するときにできていたメソッドとして、「ごはんおかず法」というのがあり、 これは「おかず」になるものをおかずが登場すべき順番に並べて、足りないおかずがあったら調達し、揃ったところで 間を「ごはん」でつないでいく、というやり方です。おかずは
です。
ごはんは当然、自然言語です。
ごはんが主役を張るのは "Introduction" で、当該研究分野の現状を概観し、問題点を述べ、これまでの取り組みを紹介し、 当該研究が解決する課題とそのあらすじを述べます。ここは当然、最後に作成することになるのが普通で、 全体のストーリーが固まってはじめて着手可能になるからです。私がもっとも苦手としているのもここで、 基本的に他の人の問題意識などはあずかりしらぬところでもあり、また、当面、顧客が直面している課題を解決したにすぎないので、 これまでのいきさつもわざわざ調べないといけないのは面倒でもあります。
おかずはある程度手持ちがあるので、「関係ない論文を2報並べてみました」というレベルでとりあえず テンプレートのファイルに並べてみます。
しかし全くごはんが書けません。どうすんねんこれ。
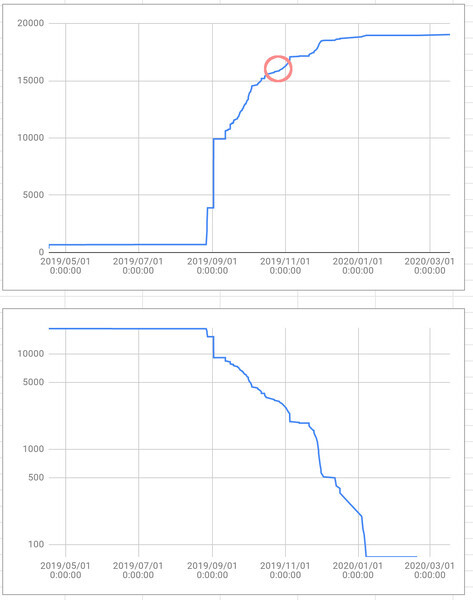
下はコミットログから再構成したD論進捗です。 縦軸は日々の作業量(行数)の累積です。
for c in `git log | grep '^commit' |sed -e "s/^commit //"` do git show $c | grep '^Date:' | sed -e "s/^Date\: //g" >> ~/date.csv done
こうやって日付を取り出したら、同様にして
git show $c | grep '^[+|-]' | wc -l >> ~/lines.csv
こうやると作業した行数が取り出せます。
4/16にリポジトリを初期化してから8月まで何もしていません。 8末にドラフトを出すよう言われていたので、とりあえず何か書くか、となって意味の通らない英文を二週間ほど 書いたり消したり10000行ほどやっています。 8末ぐらいに「半年のばずか?お?」と藤原先生に言われてブーストしますが、 要するに全く解らないまま書いているので意味の通らない英語を書いてしまうわけです。
同じデータを少し違う視点から見たものがその下のプロットです。
最終的な作業量までの残り作業量の進捗を対数グラフにプロットしています。ほぼ線形ですね。 時刻\(t\)としてあらゆるものは
$$1-\frac{1}{e^{t}}$$で進捗していくと考えられますが、それを裏付けるデータです。なぜこの式になるかというと、進捗は残作業量に比例するからで、 完成に近づくにつれて残作業を見出す確率が指数関数的に減少するのです。つまり50パーセントのものを75パーセントにもっていくのと98パーセントのものを99パーセントにもっていくコストは同じというわけです。よく言われる話ですが実際にこんな数理的裏付けがあるんですね。 なお、このプロットによれば作業量が1行未満になるまであと100日ぐらいかかりそうw
二つ目のプロットから、大きく見れば作業は終始一貫したペースで進んでいたわけだけれど、 じつは、一つ目のプロットで円で示した時点で、計測には現れないけれど主観的には不連続な変化がありました。 この日、自己相似性についての定義を原稿に入れました。
自己相似という話自体は既に採録されていた論文にも出てたんだけど、
$$X=\bigcup \limits_{i\in I} h_i(X)$$このように式で書いたのは初めてで、 先にも言ったように式で書いて初めてわかる事というのは案外あるもんです。 集合X が自己相似的であるとは インデクスの集合, \(I\) と中への位相同型写像の集合 \(\{ h_i : i \in I \}\) について上記の条件を 満たす事です。
真部分集合と位相同型なので、Xは必然的に無限集合で、そりゃ当然の話で、どこまでいっても自分と同型なのが自己相似なので、 必然的に厳密な話は無限集合に限定されてしまう。一方、我々が扱うデータは常に全て有限です。 ならば、そもそも有限の対象が自己相似っておかしくない?という事になります。 しかし、こう考えてみたらどうか。つまり時刻tが無限の時に極限として上式を充足するような そういう発展的な構造も、自己相似の仲間に入れてやってもいいじゃない。
さらに言うならば、これ自体が構造を生成する仕組みを与えている。 できあがったものの特徴であると同時に、発展の足跡でもあるのだ。
\(t\rightarrow \infty\) の時にこの式を満たすようなものも自己相似という事にしましょう、と雑に自然言語で言うのは簡単ですが、 これを俺がうけた教育の観点からまともな記述に直すのはかなり大変で、さすがにそれをやっていると締切りに間に合わない(年内に 副査の先生にドラフトを送る約束だった)ので本文に盛り込むことはできなかったが、 今後の課題とすべき話がまさかこんな、 生活に不自由があるために選択の余地無く続けている業務の中から発生してくるとは!!
こうして、構造の頑健さ、自由度、スケーラビリティをもたらすのが自己相似性であり、一見するとそれが失われているように見える データであっても、観測できないどこかに隠れている、として全然関係がなかった二つのトピックに、 偉大なる自己相似性の伏線が回収されることで救済がもたらされるのです。
これが自由意志というものなのか?などと造物主によって魂を吹き込まれたブリキの玩具の状態となって脱稿したのでした。
寺ではなく大学が人類の知的限界を規定するようになって、どれくらいでしょうか。日本でいえば、せいぜい100年少々というところでしょう。 国によってその制度的、経済的な位置づけは様々で、一概に言うことはできないが、 総じて言えば非常に厳しい状態にあるようです。 たとえば研究室にソファーやちゃぶ台があってみんなでお茶をしながら仕事以外の事も含めて楽しく話あう、 なんて事がいまは研究室では許されないのだ、 という話をイギリスの(日本ではなく!)大学の先生がしているのです。
それらの難しさのうち、どれぐらいの割合が次の理由に起因するのかはわからない。 もしかしたら充分な資金さえあればそれでいいのかもしれない。 しかし、制度化された自由意志という存在自体が抱えている矛盾に幾分かは起因しているという事はないだろうか。
自分が自分のパトロンとなって研究を行うために貴族やブルジョワである必要はない。 そういう社会が到来しつつあるとすれば、それは確かに世の中が良くなっていると言ってもいいのではないでしょうか。 いろいろと難しい事も多い現代社会ですが、我々はやっていくしかないのです。
かかった費用
学費等1900K
論文投稿費用 150K
交通費 200K
他、学会発表なども必要ですがこれは家族旅行にしてしまったので学会費用が50K ぐらい。 計 2300K円ぐらい。