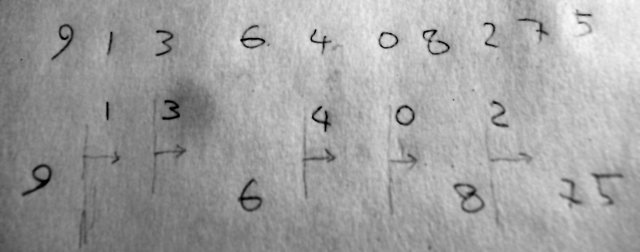
ぼくは情報科学出身といっても数学系のゼミだったし、 情報処理演習は、とりあえずコンパイラだけ通るけどバイナリは動かない ようなコードを提出してたくらいのポンコツ脳味噌だったから、 とりあえず有限時間以内に計算が終ればそれでいいや。 最大限譲歩しても多項式時間なら全然オッケー。 Ackerman 関数みたいのはさすがに具合悪いけんな。 くらいの感じだったわけです。
が、 最近の仕事では現実に存在するデータを取り扱うものが多くなっているために、 実際に動いてもらわないことにはどうしょうもない。 現実世界では、多項式時間といっても それが線形なのか2乗なのかで全然違うわけですよ。
問題が明らかに再帰な形をしている場合は、 いままで何の疑いもなく再帰を使って来ましたが、 そうでない場合は、式をそのまま書いてました。 2乗だとすぐ動かなくなります。それでは仕事になりませんから、 とりあえず手始めに、今回は分割統治法というのを憶えてみた。 こいつは普通に解ける問題をわざわざ再帰的に分割して高速化する、 というアプローチである。 そう。再帰をつかえば、いや再帰だけが複雑さを克服する唯一の手段なのだ!
分割統治法の解りやすい例題は、クイックソートだと思う。 一番解りやすいかどうかは知らんが。 それに、役に立つ。これ動機として重要。 そして、こういうときは scheme の出番でしょう。 ということで、 「scheme クイックソート」で研削じゃなくて検索してみると、
(define qsort (lambda (x) (if (null? x) ()
(append (qsort (filter (lambda (y) (< y (car x))) (cdr x)))
(list (car x))
(qsort (filter (lambda (y) (>= y (car x))) (cdr x)))))))
こういうコードを見付けた。これは非常に解りやすく、 分割統治法の本質をがっちり掴んでいる。 関数 filter がソート対象リストの先頭の値を境めにして、 ソート対象リストを分割し、これをそれぞれ qsort するという設計。 統合はサブ問題1とサブ問題2の解を append で繋いでできあがり、 である。なるほどね。 分割統治了解!オッケー任しとけ!
(謝辞 上記 scheme の quick sort は n9d氏による記事 掲載コードを、私が読めるよう適宜改行インデントしたものです。 作者の名誉のため断っておきますが、 オリジナルは一行で、非常に美しく書いてあります。)
この手口が通用するのは
という条件が必要だ。もしこれが成り立てば、n * log n 以下の手数で 問題が解けることが期待できる。うまい分割がいけば、 log n 回の 分割で再帰の終点にたどりつくからだ。 だが、うまい分割が無いと、分割がn回行われたりしてしまう。 するとその他諸経費が線形だった場合 n の2乗になってしまう。 たとえば、上の例のコードは、そっくり逆順にソートしなおさねばならない場合、 境界値は常に対象リストの最大値であり、分割がn回行われてしまう。 それから分割自体の手数や統合の手数が線形より多いと、その手数は log n 個の サブ問題の中にもれなく出現するので、これまた具合が悪い。 むしろこういうのは、問題の分割になってない、とも言えるだろう。
それじゃこの手口を他の問題に応用してみよう。 わしが例題として解いてみたのはこんな問題だ。
ある数列からペアをとりだしたとき、それが大きさの順に並んでいるものは幾つあるか?
いうまでもなく、そのまま nC2 個のペアをチェックすればこんな問題は一撃で終了である。 たかだか2乗のオーダで計算終了だ。だが今の職場では2乗は却下だ。 ところでさきほど要点を三つあげたが、 これはどれか一つを取り出して順に解決していくようなものではない。 うまい分割はうまい統合とセットであって、どっちかはうまくいくが、 どっちかがダメみたいな話はありえないわけだ。 全部いっぺんに考えなければならない。
カンだけど、これは大小関係の話だから、大小順のまんなかへんの順序のやつを 境に分割すると良い感じだ。多分ね。カンだけど。 でも、仮に出現順で分割すると、前半リストのメンバ一つにつき 後半リストの各メンバといちいち比較が必要になって、 統合の手間がnの2乗になってしまう。 これでは分割するだけ損してるわけで、問題の分割に全然なってないぞ。
十分小さく分割され自明な数列になったとき、その値は0とか1とか そんな感じだろうね。 でもこれを今心配するのはあとまわしにしよう。 二つのサブ問題を手早く統合できるためには、どう割ればいい? それに境界値だって、統計処理の対象になるデータだったら リストの端っこが使える場合なんてまず無いだろ。
境界はあとで考えるとして、まずは分割されたのをどう統合するか、だろ。 なんせ、分割されたリストどうしでペアを数えなきゃ。
統合はこうすりゃええがな。 ここはさすがにスケッチを描いちゃったよ。 上の行が元のリスト。下2つが分割。4と5の間で割ってるわけ。 割った相手とポジションを比較できるように、 ここでは自分が居た場所は空席にしてある。 こうすれば、条件に合う相手が生き別れのリストに 何個あるかを計算でき、その手数も線形だ。すこし野望に近付いたぞ。 あとは自明なリストの値を考えて、再帰の端っこを terminate すれば完成だ。
自明なリストの値だが、 この分割では同着は一つのサブリストにまとまってくるので、 同じものをまとめる同値類演算をおこなったときに、 長さ1になってるやつの値を決めとけば良いでしょう。 そして、異なる2つのメンバを持つリストの分割を考えれば自明ですが、 長さ1のリストの対象ペア数は 0 です。 境界の値はどうしようかな。
演習: このアルゴリズムを実装してみる